

Today, it’s common to hear about the integration of Artificial Intelligence (AI) into everyday life, a term that was once reserved for academic or military laboratories or just a word we saw on washing machines or elevators without fully understanding what it meant. November 30th, 2022, when OpenAI took its first step, will go down in history as the day. AI became widely democratized, allowing us to generate text, images, and videos using intelligent tools.
But is it really that easy to incorporate these technologies into your business? The answer is that it’s possible, but you need to consider a large number of factors to avoid failing in the process. Many are afraid to share valuable business information, others don’t grasp the myriad opportunities surrounding these technologies, and some have tried but ended up with nothing more than hallucinations (a term commonly used to refer to answers that AI gives us and that have no sense or context) or obvious answers that somewhat diminish the potential of generative AI.
So, how can you get started with these technologies? Don’t worry, we’ll show you how to do it from scratch with a real case study we developed.
Let’s start by understanding how you can improve a process using intelligent tools.
Identifying the Problem 🤔
Defining the Solution
Solution Architecture
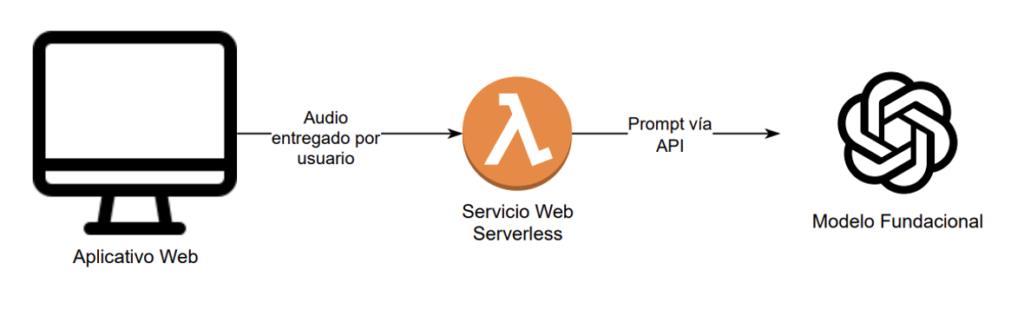
- The web application sends the audio file to the web service.
- The web service internally converts the audio to text using Python libraries for this purpose.
- The web service initiates an API integration process with the chosen foundational model, in this case, ChatGPT from OpenAI. However, there are many others like Gemini, Llama, Claude, etc. (A foundational model is essentially an AI tool trained with millions of parameters housed in vast information sources like the internet, aimed at answering user queries).
- The foundational model returns the response to the web service, which structures it to return to the web application, which processes it to fill in the form data.
A focus on what truly matters 🤓
This all sounds great, but how was the process and experience of integrating with AI? While everything sounds easy, there are certain challenges to overcome.
The first is a technical challenge in integrating with the foundational model. For example, ChatGPT provides an API communication channel using a token generated from our account.
The second challenge is sending the question and information (audio converted to text) to the model, which is essentially what we do today through the graphical interface of ChatGPT. This step may sound simple, but it’s actually one of the most challenging, as constructing a prompt (a set of instructions and questions given to the AI to find the answer or solution to a specific problem) is not easy. This process is known as Prompt Engineering and focuses on constructing the question in the best possible way to get the model to respond correctly, while also providing the necessary information. It’s crucial to keep in mind that we’re not just looking for a correct answer to our problem, but also for optimizing consumption and costs generated by these models. The costs associated with foundational models are mainly related to the number of tokens consumed, which correlates with the level of detail in the prompt—more detailed prompts require more tokens, and more tokens lead to higher billing. Keep this in mind to avoid surprises at the end of the month.
All of this can be managed with well-designed prompts and a good definition of consumption thresholds in foundational models to avoid unpleasant surprises.
The third challenge was telling the AI the format we needed to structure the response and deliver it to the web application. In this case, we used the JSON standard.
And that’s it! This is how we harnessed the power of these tools to improve a tedious and boring process. We then gave the graphical interface a redesign to make it more appealing, and the client’s satisfaction was noticeable. Time logs immediately improved by at least 30%, and their users reported a positive level of satisfaction.