In previous weeks, we published an experience of incorporating LLMs using the foundational model of ChatGPT to address a widespread
time tracking issue. In this new publication, we will share how phase 2 of this project unfolded and how we resolved the identified problems.
Recalling the problems
As we’ve always said, not everything is rosy… Previously, we mentioned earlier that one of the big problems was that the AI did not have the ability to correctly abstract the customer information and issues delivered in the prompt. Sometimes they were not accurate and it was difficult to make a match with the existing list and sometimes it did not even manage to abstract it from the content. But how could we solve this?
Solving the Challenges
If we think about it carefully, all AI needs is to know a little more about our business domain. Now the question is, how can we deliver that timely information to the AI, without falling into huge cost overruns and inefficiencies that lead to hallucinations in the foundational engine?
The answer is: using vector databases and the concept of RAG (Retrieval Augmented Generate) to deliver context to the AI.
Understanding the RAG Concept
RAG, or Retrieval Augmented Generation, is nothing more than a technique that allows us to abstract relevant information from existing documents by combining retrieval, augmentation and generation components to the queries performed. Let’s take a closer look at each phase:
Retrieval
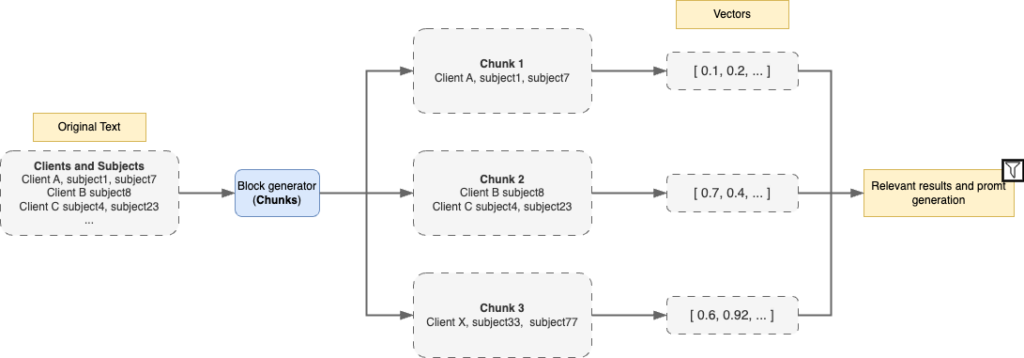
This phase allows the abstraction of information contained in information repositories and subsequent segmentation into chunks.
Augmentation
The previously retrieved information is processed to extract specific elements and contexts that can enrich the prompt delivered to the foundational model. This process ensures that the information contained in the retrieved chunks is useful and precise for the incoming task. In this stage, vector databases are utilized to calculate the distance between concepts linked to the context.
Generation
Finally, the relevant information is injected into the prompt to provide context to the foundational model, aiming to generate more effective responses and/or solutions.
And what are the advantages?
By using this type of techniques we can generate more coherent outputs avoiding hallucinations and having a grounded context. Likewise, the model can be more flexible and handle a wide range of queries and tasks, from point answers to questions, to the generation of long and detailed content.
How did we apply it?
Going back to the case study, the RAG technique allowed us to deliver the detailed list of customers and the issues associated with each of them. The results delivered by ChatGPT were much more accurate in the two problematic fields, 94% of the time the foundational engine was able to abstract the information delivered in the audio and this significantly improved user satisfaction when interacting with the time recording form.
In a nutshell
In short, incorporating RAG into our process has not only transformed the way we interact with AI, but has also elevated the quality and accuracy of our responses. By providing richer and more relevant context, we have taken an important step toward a future where AI not only responds, but understands.
But it doesn’t stop there: generative AI has the potential to revolutionize several areas of your business. Can you imagine how it could improve your processes? The key is to be proactive and explore how it can be integrated into your strategy.